Wan 2.1: An Open and Comprehensive for Advanced Video Foundation Models
Wan2.1, a novel and openly accessible suite of video foundation models engineered to significantly advance the field of video generation. Wan2.1 distinguishes itself through a combination of state-of-the-art performance, accessibility, and versatility, offering a robust platform for researchers and practitioners alike.
Key Features and Capabilities:
- State-of-the-Art Performance: Wan2.1 consistently demonstrates superior performance compared to existing open-source models and leading commercial solutions across a range of established benchmarks for video generation quality and fidelity.
- Consumer-Grade GPU Compatibility: The T2V-1.3B model within the Wan2.1 suite is designed for accessibility, requiring only 8.19 GB of VRAM. This low memory footprint ensures compatibility with a broad spectrum of consumer-grade GPUs. For instance, generating a 5-second, 480P video on an NVIDIA RTX 4090 is achievable in approximately 4 minutes, even without employing advanced optimization techniques such as quantization. Notably, this performance is competitive with certain proprietary, closed-source models.
- Multi-Task Versatility: Wan2.1 is engineered to excel in a diverse array of video generation tasks. Its capabilities extend beyond standard Text-to-Video and Image-to-Video generation to encompass Video Editing, Text-to-Image synthesis, and even Video-to-Audio generation, positioning it as a comprehensive tool for multimedia content creation and manipulation.
- Pioneering Visual Text Generation: Wan2.1 marks a significant advancement as the first video model capable of generating coherent visual text in both Chinese and English languages. This robust text generation capability substantially broadens its applicability in real-world scenarios requiring on-screen text integration.
- High-Performance Video Variational Autoencoder (VAE): At the core of Wan2.1 lies Wan-VAE, a meticulously developed video VAE. Wan-VAE delivers exceptional efficiency in encoding and decoding high-resolution videos (up to 1080P) of arbitrary length, while crucially preserving temporal coherence. This attribute makes Wan-VAE an ideal foundational component for advanced video and image generation architectures.
Empirical Evaluation
(1) Text-to-Video (T2V) Evaluation
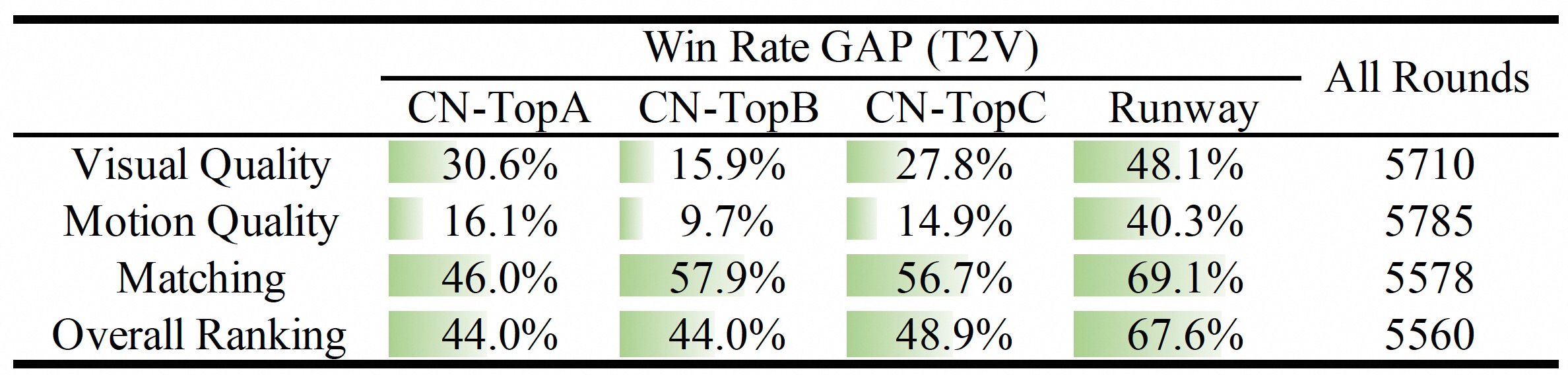
Manual evaluation of Text-to-Video generation reveals that outputs generated using prompt extension techniques with Wan2.1 exhibit superior quality and relevance when compared to results from both closed-source and other open-source models.
(2) Image-to-Video (I2V) Evaluation
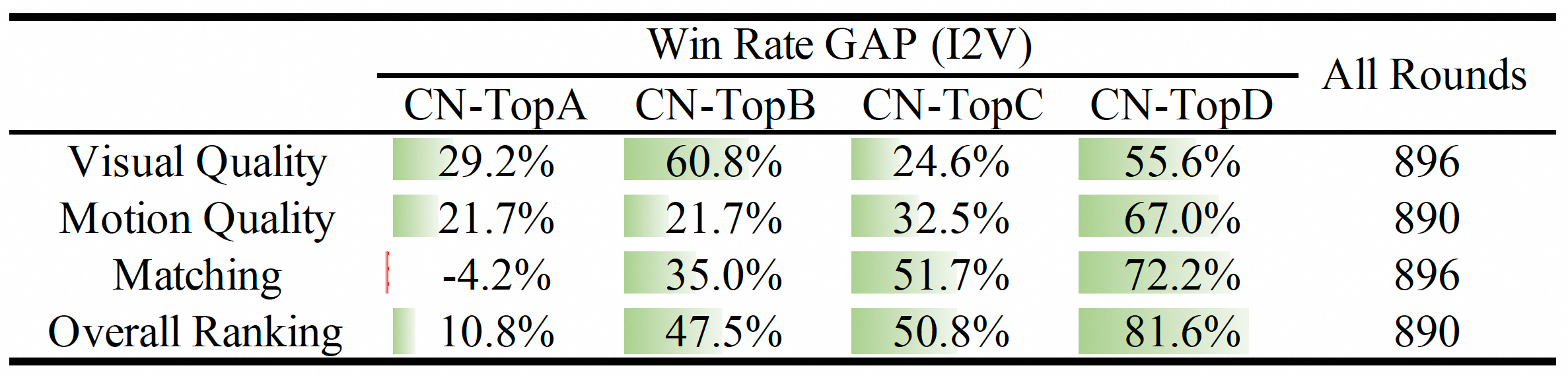
Comprehensive manual evaluations were also conducted to assess the performance of the Image-to-Video model within Wan2.1. The summarized results, presented in the table below, definitively demonstrate the performance advantage of Wan2.1 over both closed-source and alternative open-source solutions in the Image-to-Video domain.
Computational Efficiency Across GPU Configurations
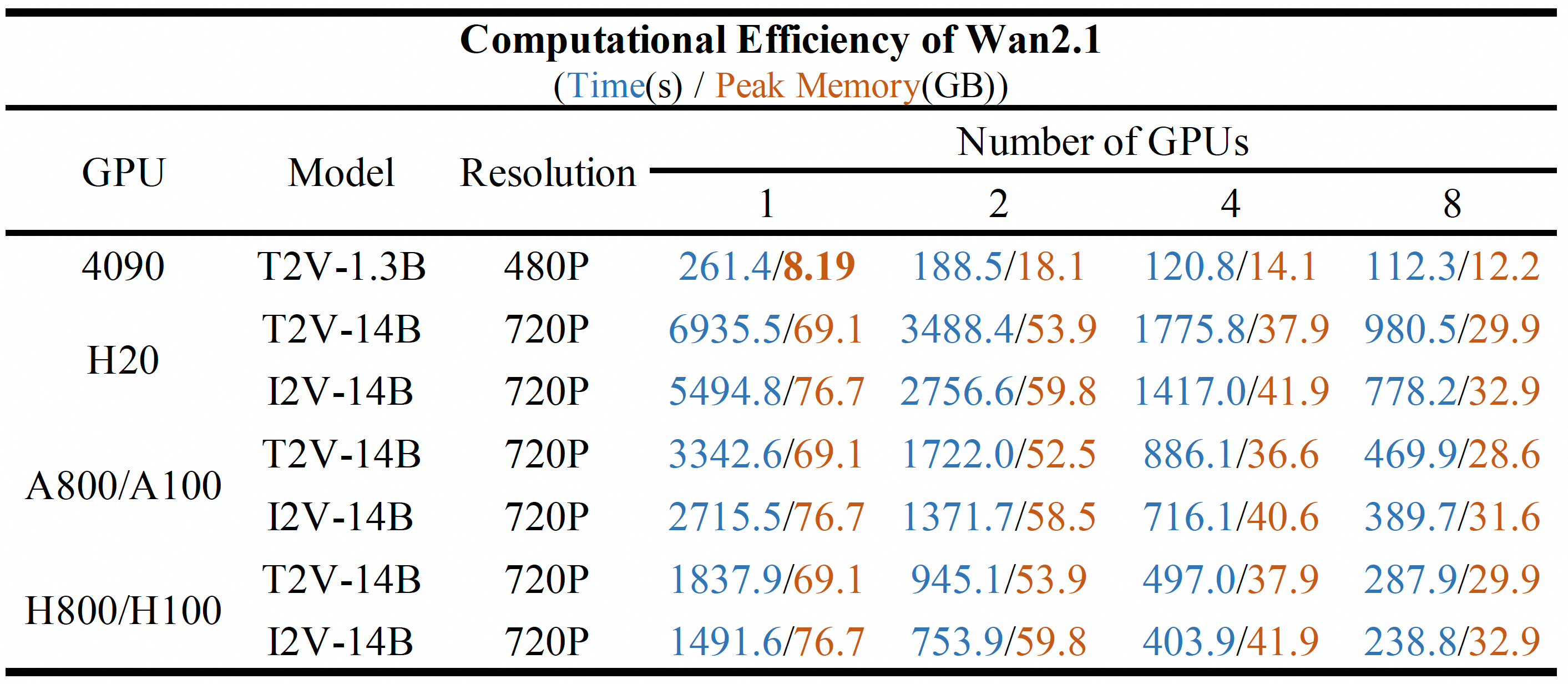
The computational efficiency of various Wan2.1 models has been rigorously tested across different GPU configurations. The results are reported in the format: Total processing time (seconds) / Peak GPU memory utilization (Gigabytes).
Note on Testing Parameters:
The presented computational efficiency benchmarks were conducted with the following parameter configurations:
(1) For the 1.3B model tested on 8 GPUs, the configuration flags were set to
--ring_size 8and--ulysses_size 1. (2) For the 14B model tested on a single GPU, the--offload_model Trueflag was enabled to facilitate operation within memory constraints. (3) For the 1.3B model tested on a single NVIDIA 4090 GPU, both--offload_model Trueand--t5_cpuflags were utilized. (4) Across all tests, prompt extension was intentionally disabled to assess baseline performance, meaning the--use_prompt_extendflag was not enabled.Performance Observation: It is noteworthy that the T2V-14B model exhibits a slightly slower processing time compared to the I2V-14B model. This is attributed to the T2V sampling process utilizing 50 steps, whereas the I2V process employs 40 steps.
Community Ecosystem
Wan2.1 benefits from and is further enhanced by contributions from the open-source community. Specifically, DiffSynth-Studio provides extended support for Wan2.1, encompassing functionalities such as Video-to-Video translation, FP8 quantization for optimized performance, VRAM optimization techniques, LoRA (Low-Rank Adaptation) training capabilities, and more. Users are encouraged to explore DiffSynth-Studio examples for practical implementations and advanced use cases.
Technical Foundation of Wan2.1
Wan2.1 is architected upon the prevalent diffusion transformer paradigm, achieving substantial advancements in generative capabilities through a series of key innovations. These innovations encompass:
(1) 3D Variational Autoencoders (VAEs)
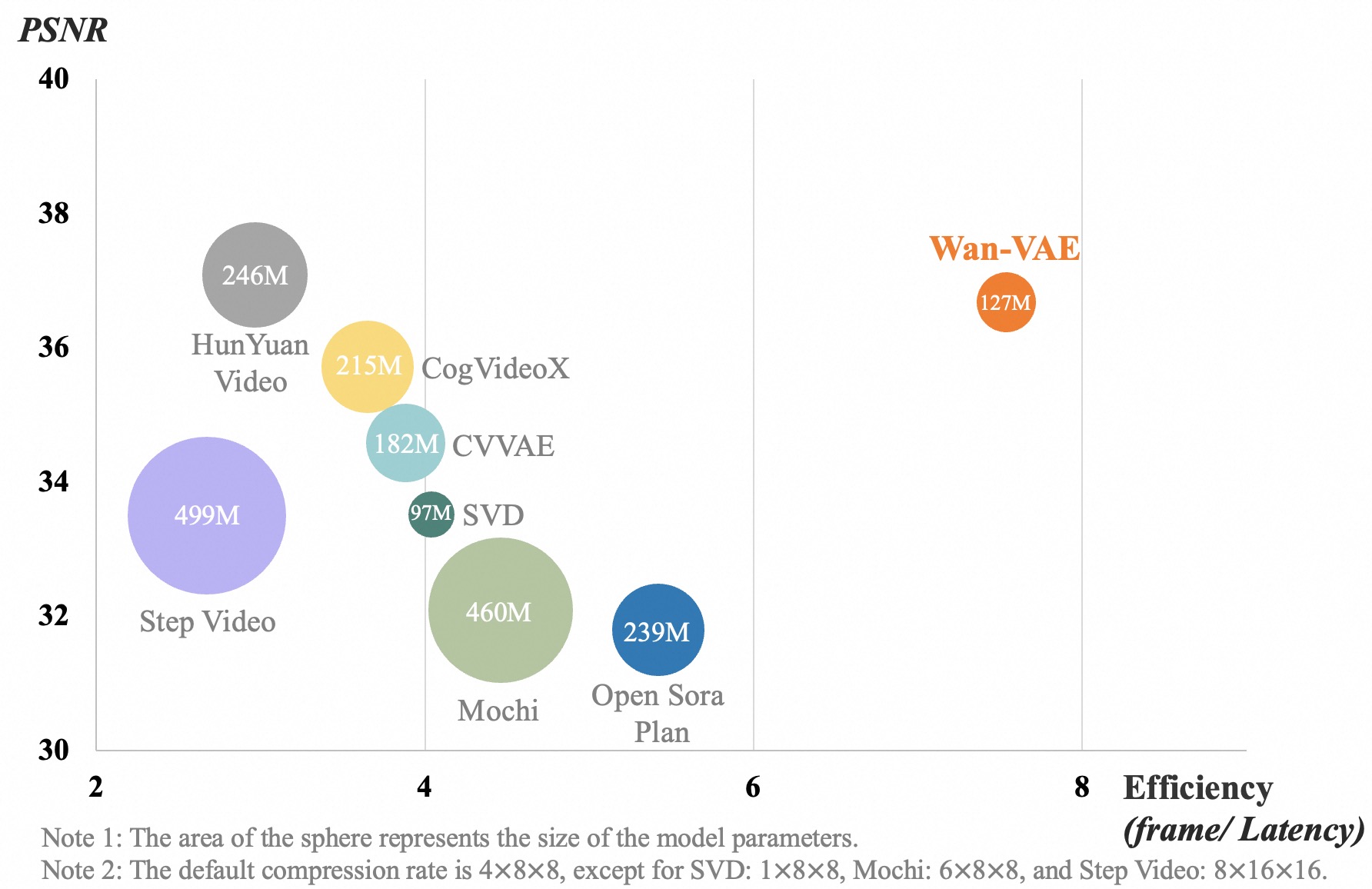
A novel 3D causal VAE architecture, designated Wan-VAE, has been developed specifically for video generation. By integrating a combination of advanced strategies, Wan-VAE achieves improved spatio-temporal compression, reduces memory footprint, and ensures temporal causality within the generated video sequences. Empirical evaluations demonstrate that Wan-VAE offers significant advantages in performance and efficiency compared to other publicly available VAE models. Furthermore, Wan-VAE is capable of encoding and decoding 1080P videos of arbitrary duration without compromising temporal information, making it exceptionally well-suited for demanding video generation tasks and long-form video content creation.
This revised version aims to present the information in a more structured and technically focused manner, suitable for documentation while retaining all essential details and the original image placements.